
3·
10 hours agoYou don’t even need a VPN to use a different DNS server.
You don’t even need a VPN to use a different DNS server.
Injecting a malicious undisclosed firmware/software update. Very private and secure. /s
That’s bullshit. There’s no reason to limit or target a specific or non-maximum CPU core usage.
That would only make sense to evade hardware faults or cooling issues. Never as a general guideline.
YouTube channels can be terminated for both repeated copyright infringement and community guideline violations. In these cases, revenues are often withheld as well. It’s possible, however, that linked AdSense accounts are treated differently.
AdSense policies can be confusing, but based on additional information provided by Google’s AI, YouTube copyright bans are most likely to result in AdSense terminations too.
This is the first time I read of an AI as a source / AI being a source for an article.
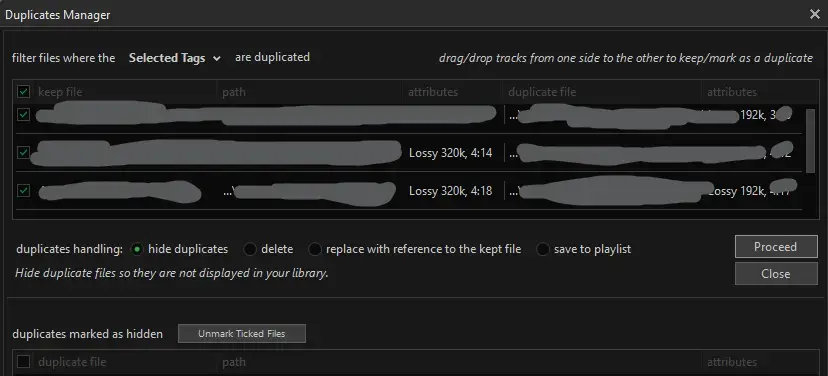
MusicBee has Tools -> Manage Duplicates
{kind=link}
Depending on what you want to scape, that’s a lot of overkill and overcomplication. Full website testing frameworks may not be necessary to scrape. Python with it’s tooling and package management may not be necessary.
I’ve recently extracted and downloaded stuff via Nushell.
document.querySelectorAll()For me, my command line terminal and scripting language of choice is Nushell:
or
Depending on the tools you use, it’ll be quite similar or very different.
Selenium is an entire web-browser driver meaning it does a lot more and has a more extensive interface because of it; and you can talk to it through different interfaces and languages.